
Ollama est vraiment un outil formidable qui vous permet d’utiliser de nombreux modèles d’intelligence artificielle en local très facilement. Je vous ai récemment écrit un tutoriel pour démarrer facilement avec Ollama et l’IA en local. Même si votre machine n’est pas très puissante, avec un processeur pas trop ancien et un peu de RAM, au moins 16 Go, vous pourrez utiliser des petits LLM directement sur votre ordinateur à la maison ou au bureau. C’est très utile pour manipuler des données et informations sur lesquelles la confidentialité est très importante pour vous.
J’en profite pour vous dire que ce n’est d’ailleurs pas le seul logiciel qui vous permet d’exécuter des LLM directement sur sa machine et il y a d’autres logiciels pour utiliser l’intelligence artificielle en local. Cela dépend surtout de vos besoins et ce que vous voulez faire. Pour faire son choix entre ces différents logiciels, cela se joue entre l’interface utilisateur, les fonctionnalités, les performances, la facilité de mise en route … En bref, il faut tester !
Ce qui m’amène à écrire cet article pour Ollama, c’est que si on ne connaît pas bien le logiciel, il a un petit défaut et pas des moindres. Par défaut, lorsque vous lancez un modèle pour faire de l’inférence, la fenêtre contextuelle est réglée à 2048 caractères. C’est une valeur qui n’est pas très élevée même sur des machines modestes, il est possible de pousser un peu plus pour avoir des réponses de meilleure qualité !
Les tokens et la fenêtre contextuelle, qu’est ce que c’est ?
Revenons un peu aux bases, il faut bien comprendre ce que c’est un token et la fenetre de contexte lorsque vous utilisez un LLM et l’IA en général.
Pour faire simple, un token, c’est un peu l’unité de base avec laquelle le modèle d’intelligence artificielle va travailler. Imaginez que vous donnez un texte au LLM. Il ne va pas le lire mot par mot comme nous, mais il va le découper en petits morceaux, ces fameux tokens. Un token peut être un mot entier comme « chat », mais aussi une partie d’un mot plus complexe comme « anti » et « constitutionnellement » (qui seraient décomposés), ou même un simple signe de ponctuation ou un espace.
C’est un peu comme si le LLM découpait votre phrase en petites briques élémentaires pour mieux la comprendre et la traiter. Le nombre de tokens n’est donc pas toujours égal au nombre de mots, mais c’est une approximation utile. Ces tokens sont ensuite transformés en chiffres, car les modèles d’IA, ce sont avant tout des maths ! Il est possible de compter les tokens que vous manipulez à l’aide de Tiktoken qui est très utile.
Maintenant que vous savez ce qu’est un token, parlons de la fenêtre contextuelle (ou « context window » en anglais). C’est tout simplement la quantité maximale de tokens que le LLM peut prendre en compte en même temps. Pensez-y comme à la mémoire vive de travail du modèle pour une conversation ou une tâche donnée. Elle inclut à la fois votre question (le « prompt ») et la réponse que le modèle va générer. Plus cette fenêtre est grande, plus le modèle peut « se souvenir » de ce qui a été dit précédemment dans la conversation ou d’une plus grande portion d’un document que vous lui soumettez. Cela lui permet de donner des réponses plus cohérentes, de mieux suivre des instructions complexes et de moins « perdre le fil ». Si une conversation devient trop longue et dépasse la taille de cette fenêtre, le modèle commencera à « oublier » les informations les plus anciennes pour faire de la place aux nouvelles.
Le problème de la limite par défaut à 2048 tokens avec Ollama
Une fenêtre de 2048 tokens, comme celle par défaut dans Ollama pour certains modèles, peut parfois être un peu juste si vous avez besoin de discussions longues ou d’analyser des textes conséquents. Augmenter cette fenêtre, c’est donc donner plus de « mémoire à court terme » à votre IA pour qu’elle travaille mieux. Soit avec plus données en entrée via le prompt et l’appel API, soit au fil de la discussion pour ne pas oublier ce qui s’est dit juste avant.
Alors, pourquoi Ollama met-il cette barrière des 2048 tokens par défaut ? Je ne suis pas le seul à me poser cette question mais je n’ai pas trouvé d’explication explicite venant de leur équipe. C’est probablement pour assurer une compatibilité maximale et une expérience utilisateur fluide dès le départ, même sur des configurations matérielles modestes. En démarrant avec une fenêtre de contexte plus petite, Ollama s’assure que la plupart des utilisateurs pourront lancer un modèle sans immédiatement saturer leur RAM ou attendre indéfiniment une réponse. C’est un peu un réglage « passe-partout » par défaut.
Heureusement, cette limite de 2048 tokens n’est souvent pas une fatalité imposée par le modèle lui-même. Comme nous l’avons vu, il s’agit plutôt d’un réglage conservateur d’Ollama pour le lancement initial. La plupart des modèles récents sont capables de gérer des contextes bien plus importants. De plus, peu importe la valeur par défaut, maîtriser sa fenêtre contextuelle avec précision permet d’éviter d’autres soucis dans le futur. Au moins, on sait avec précision qu’elle est la taille de cette fenêtre de contexte si on la défini nous-même.
Le premier réflexe à avoir est d’aller jeter un œil sur la page du modèle que vous utilisez, directement sur la bibliothèque de modèles Ollama. Lorsque vous sélectionnez un modèle, cliquez sur la bonne variante et cliquez sur Model pour avoir avoir les détails techniques :
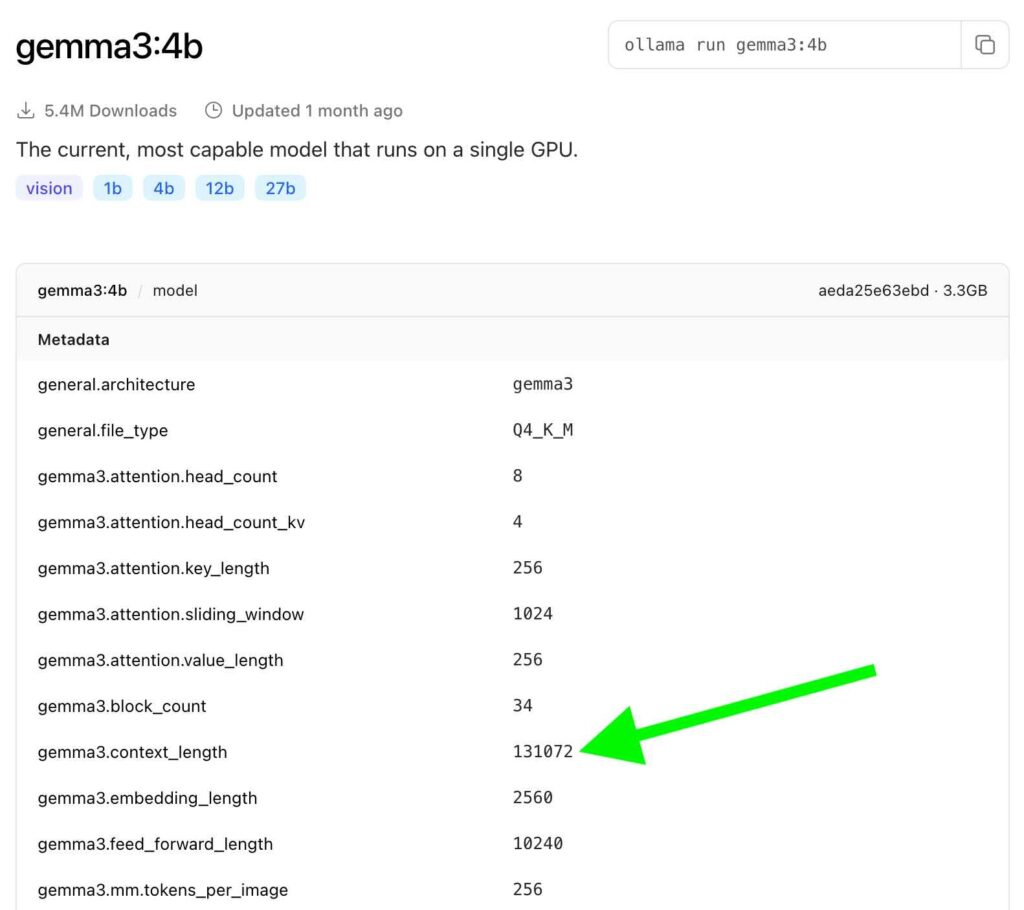
Vous y trouverez souvent une information cruciale, parfois nommée llama.context_length, general.context_length ou une variation de ce nom, indiquant la fenêtre de contexte maximale pour laquelle ce modèle a été entraîné ou est optimisé. Ici, on voit que la limite théorique maximale est 131072 à condition d’avoir assez de mémoire vive sur la machine.
Augmenter le paramètre de fenêtre de contexte sur un LLM dans Ollama
La bonne nouvelle, c’est que c’est assez simple, même si cela demande de passer par la ligne de commande. Ouvrez votre terminal et tapez la commande pour lancer le modèle dont vous voulez modifier le contexte. Par exemple :
ollama run gemma3:4bVous verrez apparaître le prompt >>> indiquant que vous pouvez interagir avec le modèle.
Le paramètre qui contrôle la taille de la fenêtre de contexte dans Ollama s’appelle num_ctx. Vous allez utiliser la commande /set parameter pour le modifier. Par exemple, pour passer à une fenêtre de 8192 tokens :
>>> /set parameter num_ctx 8192
Set parameter 'num_ctx' to '8192'Ollama vous confirme que le paramètre a bien été pris en compte. Pour ne pas avoir à refaire cette manipulation à chaque fois, vous allez sauvegarder cette configuration comme une nouvelle « version » de votre modèle. Il est conseillé de lui donner un nom explicite, par exemple en ajoutant la taille du contexte :
>>> /save gemma3-4b-8k
Created new model 'gemma3-4b-8k'Et voilà ! Vous avez créé une nouvelle variante de votre modèle, gemma3-4b-8k, qui utilisera par défaut une fenêtre de 8192 tokens. Vous pouvez maintenant quitter le prompt du modèle avec :
/byeDésormais, pour lancer votre modèle avec la fenêtre de contexte étendue, il vous suffira de taper :
ollama run gemma3-4b-8kAttention, augmenter la fenêtre de contexte consomme plus de mémoire vive (RAM). Beaucoup plus. Chaque token supplémentaire que le modèle doit garder en mémoire pour le contexte demande des ressources. Imaginons que vous ayez tenté de pousser le bouchon un peu plus loin avec gemma3:4b, en visant une fenêtre de 32768 tokens :
ollama run gemma3:4b
>>> /set parameter num_ctx 32768
Set parameter 'num_ctx' to '32768'
>>> /save gemma3-4b-32k
Created new model 'gemma3-4b-32k'Si vous essayez ensuite de lancer ce modèle gemma3-4b-32k sur une machine qui n’a pas la RAM suffisante, vous allez rencontrer un message d’erreur sans équivoque :
ollama run gemma3-4b-32k
Error: model requires more system memory (23.3 GiB) than is available (8.9 GiB)Oups ! Le message est clair : le modèle avec cette fenêtre de contexte de 32k tokens exigerait 23.3 Go de RAM, alors que votre système n’en a que 8.9 Go de disponibles à ce moment-là. C’est pourquoi votre tentative avec 8192 tokens (8k) a fonctionné, car elle était plus raisonnable par rapport aux capacités de la machine que j’étais en train d’utiliser. Si vous utilisez ollama ps :
ollama ps
NAME ID SIZE PROCESSOR UNTIL
gemma3:4b c0494fe00251 4.3 GB 100% CPU 3 minutes from now
gemma3-4b-8k:latest bff0d8d88c6e 8.3 GB 100% CPU 4 minutes from nowOn remarque aussi que la taille indiquée (SIZE) a considérablement augmenté, passant de 4.3 Go à 8.3 Go dans cet exemple ! Ce n’est pas toujours une augmentation directe de la taille du fichier sur le disque de la même manière, mais cela reflète souvent la charge mémoire accrue que le modèle, ainsi configuré, peut représenter une fois chargé.