
En ce moment, j’ai un client qui souhaite automatiser au maximum de taches au sein de son entreprise à l’aide de l’intelligence artificielle. Très bien, mais il faut savoir qu’il y a plusieurs facteurs à prendre en compte. Il y a quelque temps, je vous avais fait un tutoriel pour utiliser l’API d’OpenAI avec PHP en utilisant cURL. Aujourd’hui, nous allons plutôt voir comment tenter de mesurer le coût d’un appel API avec Python avant qu’il ne parte vers les serveurs d’OpenAI. En effet, lorsque vous utilisez l’API d’OpenAI pour interroger leur modèle d’intelligence artificielle, il y a 2 choses à prendre en compte.
On le constate dans mon comparatif sur le prix des API pour utiliser les différents LLMs, il y a la notion d’input et output. Comme leur nom l’indique, il s’agit du coût et donc ce que vous allez payer pour chaque million de tokens échangé en entrée et sortie. Selon les politiques tarifaires des différentes sociétés d’intelligence artificielle et surtout la puissance du modèle utilisé, c’est plus ou moins cher. Sur les anciens modèles d’intelligence artificielle qui sont maintenant sortis depuis longtemps, c’est devenu très accessible avec par exemple le cas de gpt-3.5-turbo qui sera largement suffisant pour des petites taches. Du côté d’Anthropic, c’est un choix volontaire avec Claude 3 Haiku qui est lui très peu cher. Par contre, pour des choses plus complexes, il faudra bien évidemment aller sur des modèles d’intelligence artificielle plus puissant.
Pour le même nombre de tokens vous n’allez pas du tout payer la même chose, il faut donc bien choisir le modèle à utiliser. Ce n’est pas tout, car pour mon client, j’ai souhaité réduire les coûts tout en obtenant les mêmes résultats ou presque dans la réponse. J’ai donc tenté au maximum de compresser et de rationaliser ce que je mets dans l’input tout en évitant au maximum la perte d’information utile pour que le LLM comprenne bien ma demande. D’ailleurs, revenons aux bases avant d’aller plus loin !
C’est quoi un token dans l’intelligence artificielle ?
Un token dans le contexte de l’intelligence artificielle, et plus spécifiquement dans le traitement du langage naturel (NLP), est un élément unique ou une unité de texte que l’IA traite individuellement. Lorsqu’un modèle d’IA analyse du texte, il commence par le diviser en plus petites unités. Ces unités peuvent être des mots, des parties de mots, des caractères, ou des groupes de mots. Chaque unité individuelle est appelée un « token ».
Les tokens servent à simplifier le traitement du texte par les modèles d’IA. En utilisant ces unités, le modèle peut mieux comprendre et analyser le texte pour accomplir des tâches comme la classification de texte, la génération de réponses, ou la traduction automatique. La méthode qui consiste à diviser le texte en tokens s’appelle la « tokenisation ». Les algorithmes de tokenisation varient selon le modèle d’IA et l’objectif. Par exemple, certains modèles préfèrent utiliser des mots entiers comme tokens, tandis que d’autres utilisent des sous-mots pour être plus flexibles face aux variations linguistiques.
Les tokens permettent aux modèles d’IA de transformer du texte brut en une représentation numérique compréhensible pour l’IA. Cette transformation est essentielle pour l’entraînement des modèles, car elle permet de transformer le texte en une série de valeurs numériques que le modèle peut traiter. C’est un concept clé qui permet aux modèles de comprendre et de manipuler le texte de manière efficace.
Comment compter le nombre de tokens avec une requête API avec Tiktoken en Python
Maintenant, que tout est clair, on va pouvoir rentrer dans le vif du sujet. Comment compter et estimer combien va nous coûter un appel API vers OpenAI avec un script Python. OpenAI nous propose d’ailleurs une interface en ligne pour compter les tokens et rendre la chose plus graphique.
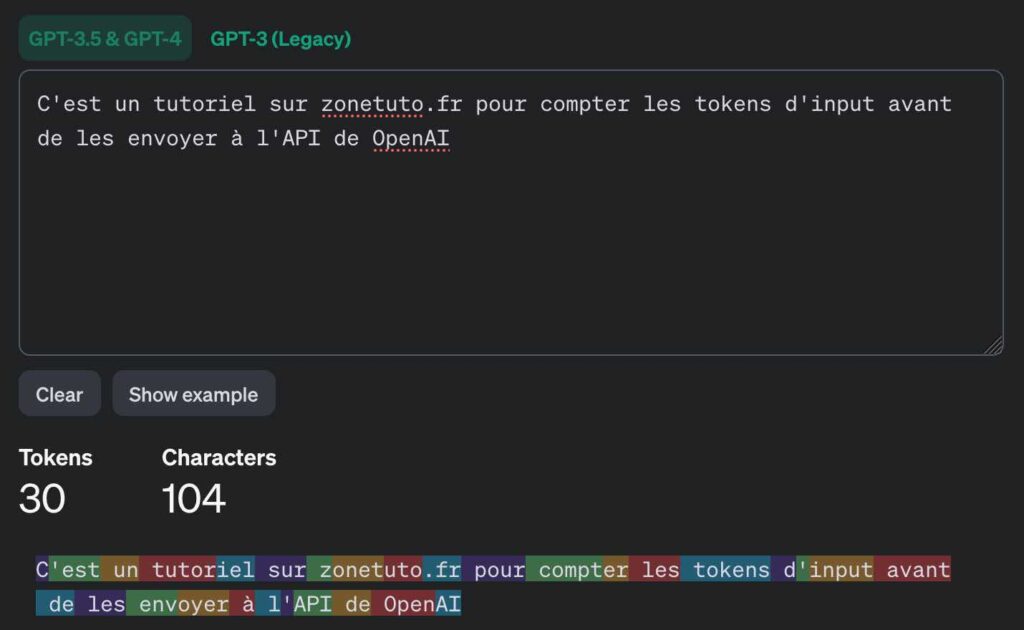
Il est possible d’utiliser cette page autant que vous le souhaitez, mais moi, je veux automatiser tout ça donc il faut avoir ce traitement dans notre script Python. Cela sera éventuellement utile stocker cette information même si OpenAI propose un tableau de bord plutôt clair sur ce que vous allez payer.
Pour avoir un découpage correct de notre texte et le vrai nombre de tokens qui sera compté du côté de l’API, OpenAI nous propose Tiktoken qui est directement maintenu par leurs équipes. Pour l’utiliser, c’est très facile et voici un exemple de script Python qui utilise Tiktoken pour compter le nombre de tokens de votre input :
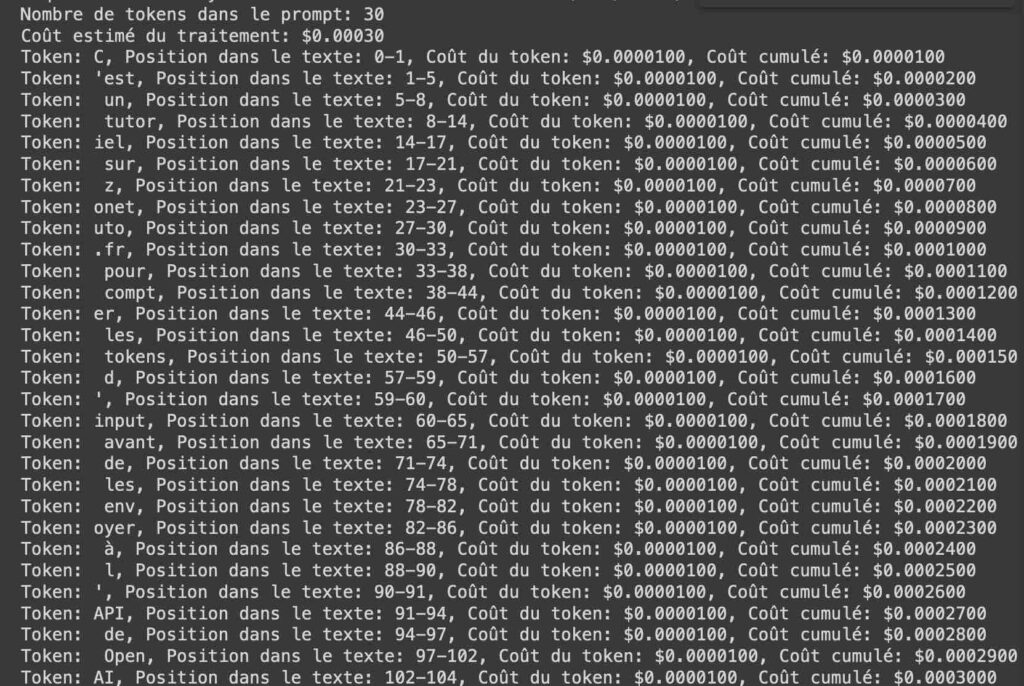
!pip install tiktoken import tiktoken # Choisissez le modèle que vous allez utiliser avec OpenAI, par exemple, GPT-4-turbo enc = tiktoken.encoding_for_model("gpt-4-turbo") # Coût par million de tokens cost_per_million_tokens = 10.00 # 10 dollars pour 1 million de tokens # Coût par token cost_per_token = cost_per_million_tokens / 1_000_000 # Texte du prompt prompt_text = "C'est un tutoriel sur zonetuto.fr pour compter les tokens d'input avant de les envoyer à l'API de OpenAI" # Obtenez la liste des tokens tokens = enc.encode(prompt_text) # Comptez le nombre de tokens token_count = len(tokens) print("Nombre de tokens dans le prompt:", token_count) # Coût total estimé total_cost = token_count * cost_per_token print(f"Coût estimé du traitement: ${total_cost:.5f}") # Afficher chaque token avec ses détails et le coût cumulé decoded_tokens = [] cumulative_cost = 0.0 start = 0 for token in tokens: # Décodage du token en chaîne de caractères decoded = enc.decode([token]) decoded_tokens.append(decoded) # Trouver la position de départ du token dans le texte start = prompt_text.find(decoded, start) end = start + len(decoded) # Coût du token actuel token_cost = cost_per_token cumulative_cost += token_cost print(f"Token: {decoded}, Position dans le texte: {start}-{end}, Coût du token: ${token_cost:.7f}, Coût cumulé: ${cumulative_cost:.7f}") # Mettre à jour la position de départ pour le prochain token start = end
J’ai créé et partagé un Google Colab si vous voulez l’exécuter directement en ligne pour tester rapidement. Avec ce script, j’obtiens un résultat cohérent entre Tiktoken et l’outil Tokenizer en ligne d’OpenAI :
Nombre de tokens dans le prompt: 30 En me basant sur les prix du million de token d’input selon le modèle d’intelligence artificielle utilisé, j’ai aussi ajouté un simple calcul qui estime le coût en dollars de votre requête vers l’API. Vous pourrez bien sûr adapter ce script selon vos besoins et le rendre moins bavard.
Même si l’interprétation des autres modèles d’intelligence artificielle ne sera pas forcément la même, vous pouvez tout de même utiliser Tiktoken pour estimer le coût de vous input sur Claude 3 ou encore chez Mistral AI. Si vous avez une machine puissante avec un bon processeur et un peu de mémoire vive, vous pouvez aussi exécuter le nouveau Llama 3 directement en local.