
Les choses s’étaient un peu calmées en ce début d’année, et encore, d’un calme plutôt relatif, mais les choses repartent de plus belles. Il y a eu beaucoup d’annonces ces derniers jours. Sur les LLM classiques de texte, nous avons des nouveautés du côté de Mistral avec Le Chat, mais aussi chez Anthropic avec Claude 3 qui est lui aussi très performant avec une API pour utiliser le LLM moins chère que chez OpenAI. Après Stable Diffusion 3, c’est au tour de Meta AI de faire une grande annonce qui devrait encore bien bousculer le domaine de l’intelligence artificielle grand public.
Ce qui est bien avec ces solutions ouvertes, c’est que vous pourrez encore une fois faire tourner ce nouveau modèle d’intelligence artificielle Llama 3 en local comme ses prédécesseurs. Bon, bien évidemment, c’est possible à condition d’avoir une machine suffisamment puissante. C’est plutôt une bonne nouvelle pour ceux qui veulent protéger au maximum la confidentialité de leurs données. Il existe déjà GPT4All pour faire tourner et utiliser des LLM en local, mais ce n’est pas le seul. Je suis déjà en train de préparer un article pour vous proposer toutes les alternatives disponibles. Quoiqu’il en soit, le but est toujours le même, faire fonctionner un modèle d’intelligence artificielle directement sur sa machine pour éviter toute fuite potentielle de données.
Quoi de neuf avec Llama 3 de Meta AI ?
Forcément avec nouveau modèle d’intelligence artificielle annoncé en grande pompe, on s’attend à une amélioration notable des performances. C’est encore tout frais et ça date d’hier soir donc il faudra encore attendre des benchmark plus poussés. Une chose est sûre, il va y avoir du fine-tuning du LLM de Facebook dans tous les sens et l’écosystème qui s’était créé autour des précédentes versions va encore plus s’étendre et surtout s’améliorer.
Pour la partie un peu plus technique, on apprend différentes choses avec cette annonce de Meta AI. Déjà, le modèle Llama 3 a été entraîné sur vachement plus de données que Llama 2, mais vraiment plus !

Llama 3 8B et 70B qui ont été entraînés sur plus de 15 trillions tokens. L’ensemble de données d’entraînement est sept fois plus important que celui utilisé pour Llama 2. Il faut savoir que trillions en anglais, ce sont mille milliards ce qui nous donne la belle bagatelle de 15 000 milliards de tokens d’entraînement. On commence à atteindre des chiffres vraiment impressionnants. Imaginez la suite, ça donne le vertige …
Ah oui, c’est l’occasion d’aborder les deux versions du modèle d’intelligence artificielle Llama 3. Pour le moment, terminé les versions intermédiaires et on passe direct du modèle utilisable par tout le monde ou presque qui est le Llama 8B ou sinon la grosse artillerie avec le classique Llama 70B. Au passage, la fenêtre de contexte a été améliorée de 4096 à 8192 tokens entre Llama 2 et Llama 3 ce qui est plutôt appréciable. En parlant de tokens, Llama 3 utilise un nouveau tokenizer qui est capable de supporter une fenêtre de contexte jusqu’a 128k tokens. Il offre une efficacité nettement améliorée pour les jetons. En plus, malgré un modèle 8B plus grand, Llama 3 maintient une efficacité d’inférence équivalente à celle de Llama 2 7B. Encore une bonne nouvelle.
Du côté des performances, même si c’est à pondérer face à la réalité lorsque l’on utilise des LLM pour de vraies taches courantes, ils annoncent des performances meilleures que certains noms que l’on commence à connaître.
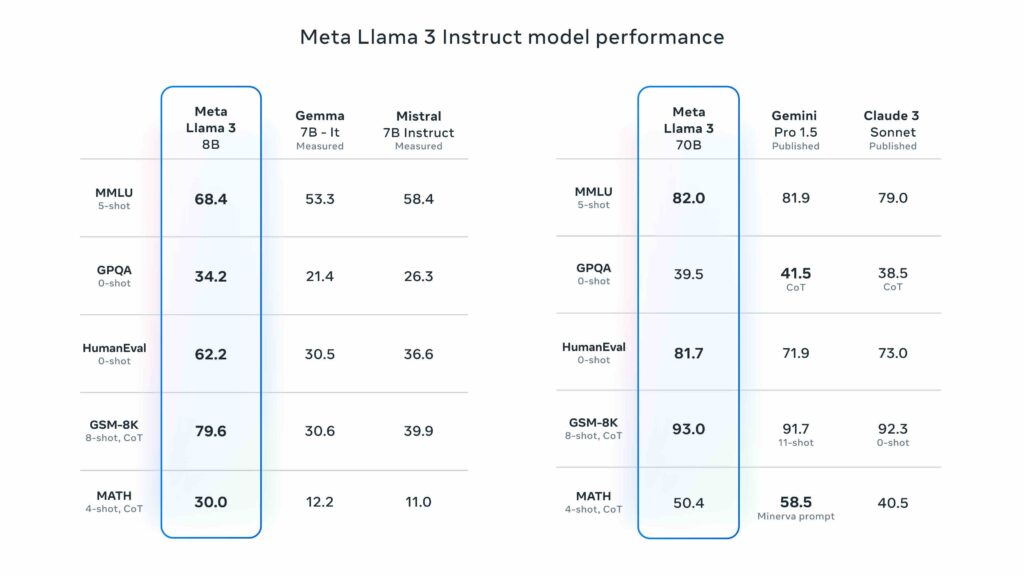
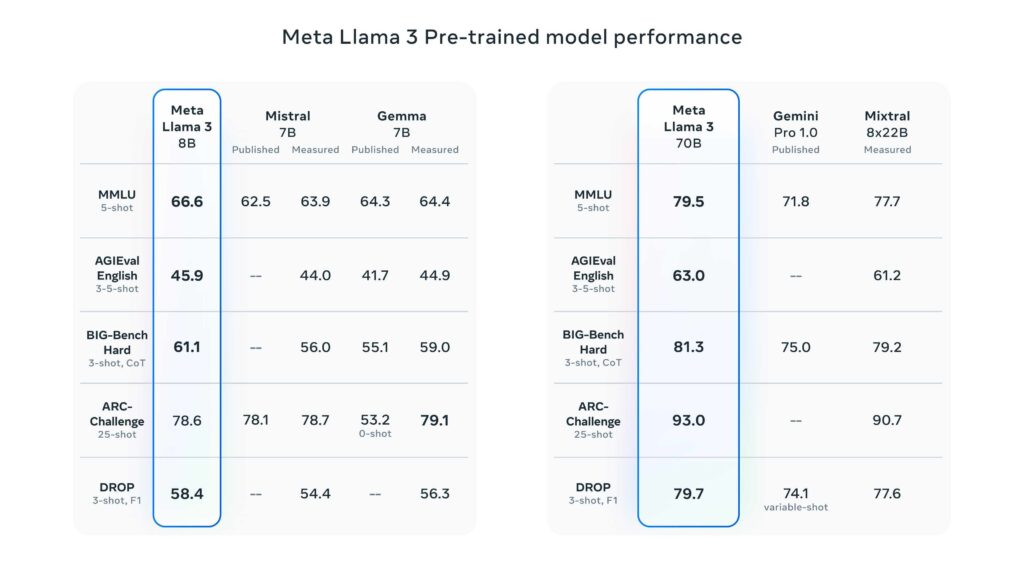
Llama 3 est donc annoncé dans certains benchmarks comme meilleur que Gemini Pro 1.5, Claude 3 Sonnet et surtout Mixtral 8x22B qui fait sensation ces derniers temps avec son approche différente. Bon, il s’agit bien évidemment de benchmarks triés sur le volet et chacun leur fait dire ce qu’il veut, c’est comme avec les nouvelles cartes graphiques ou les processeurs, ce qui compte, c’est ce que ça donne en utilisation réelle. On le verra dans les prochains jours.
Comment utiliser Llama 3 facilement ?
Dans le début de cet article, je vous ai parlé de GPT4All, mais il y a un autre client qui fait beaucoup de bruit, il s’agit d’Ollama. C’est le client local pour exploiter les LLMs qui est, je pense, aujourd’hui le plus abouti. Ce n’est pas dit comme ça en l’air, car la communauté et les développeurs sont extrêmement actif et il est déjà possible d’utiliser Llama 3 avec Ollama !
Ce n’est pas le but de cet article et je vais avoir l’occasion d’y revenir ici dans de futures publications, mais si vous avez l’habitude d’Ollama, pour utiliser Llama 3 c’est vraiment très facile. Pour le lancer, il vous suffit de lancer cette commande :
ollama run llama3
ollama run llama3:70bSi vous souhaitez télécharger Llama 3 et l’utiliser comme bon vous semble, vous pouvez passer par cette page pour récupérer le modèle d’intelligence artificielle chez Meta AI. N’hésitez pas à me dire ce que vous pensez ce nouveau Llama 3 dans les commentaires et on se retrouve très vite pour en reparler plus en détails !