Je continue ma petite série d’articles sur l’intelligence artificielle en général, et aujourd’hui nous allons parler de conversion pour utiliser l’IA en local sans carte graphique. Si l’intelligence artificielle et l’open source vous intéressent, vous êtes sûrement déjà arrivé sur le site web Hugging Face lors de vos recherches sur ce domaine passionnant. En effet, celui-ci regroupe une grande communauté de gens qui partagent leur travail dans le domaine de l’intelligence artificielle. Le seul problème, c’est que tout n’est pas utilisable directement et il faudra faire quelques actions de notre côté pour pouvoir utiliser ça sur notre processeur et faire de l’inférence.
Depuis l’arrivée de ChatGPT, mais aussi plus récemment Llama de Meta qui en a remis une bonne couche, les LLM (grand modèle de langage) ont gagné une grande popularité auprès du grand public et les choses bougent énormément. Dans ce tutoriel, nous allons voir comment convertir un modèle d’intelligence artificielle qui a été entraîné par quelqu’un d’autre et généreusement mis à disposition sur Hugging Face. N’oubliez pas qu’il y a de nombreuses évolutions rapides et alors qu’avant, on parlait de GGML depuis la mise à jour de Llama CPP, les conversions se font maintenant par défaut au format GGUF. Cela ne change ici pas grand-chose pour nous, mais je préfère le préciser et si ça vous intéresse plus en détail, je vous conseille d’aller voir mon article GGML vs GGUF qui vous donnera des informations supplémentaires sur ce sujet.
Installation de llama.cpp
Pour commencer, nous allons donc installer le logiciel llama.cpp qui est open source et disponible sur GitHub. Rassurez-vous, tout ce qui suit n’est vraiment pas très compliqué et je vais vous accompagner pour chaque étape.
Je précise que je suis sur une distribution Linux Kubuntu et que normalement cela devrait fonctionner de la même manière sous macOS. Pour Windows, je ne sais pas, mais cela devrait être très similaire aussi, de toute façon, c’est expliqué sur la documentation de Llama CPP.
Normalement, cette première étape devrait se passer sans la moindre encombre, il faut simplement cloner llama.cpp à l’emplacement de votre choix :
git clone https://github.com/ggerganov/llama.cppEnsuite mettez vous dans le dossier de llama.cpp et lancez le build avec make :
cd llama.cpp/
makeLe build va alors se lancer et il faudra attendre, ce n’est pas très long :
I llama.cpp build info:
I UNAME_S: Linux
I UNAME_P: x86_64
I UNAME_M: x86_64
I CFLAGS: -I. -O3 -std=c11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wdouble-promotion -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I CXXFLAGS: -I. -I./examples -O3 -std=c++11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-multichar -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I LDFLAGS:
I CC: cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
I CXX: g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
[..........]Si vous n’avez pas eu d’erreur pendant la compilation, llama.cpp est maintenant prêt à être utilisé et nous en avons terminé avec l’installation de cet outil.
Téléchargement de Vigogne sur Hugging Face avec git lfs
Si ce n’est pas encore le cas sur votre machine, il faudra dans un premier temps installer git LFS pour Large File Storage. Je ne vais pas ici rentrer dans les détails, mais la version de base de git a une limite concernant la taille des fichiers que vous pouvez récupérer. Git LFS vous permet de contourner cela et donc de télécharger des énormes fichiers. Enfin, je parle de contournement, mais c’est bien une nouvelle fonctionnalité en plus supportée par l’outil, il faut juste l’installer en plus en amont avant d’essayer de télécharger de gros repository.
C’est d’ailleurs le cas avec ce qui va suivre. Ce n’est pas énorme, mais c’est tout de même assez gros et il faut donc passer par ce git LFS.
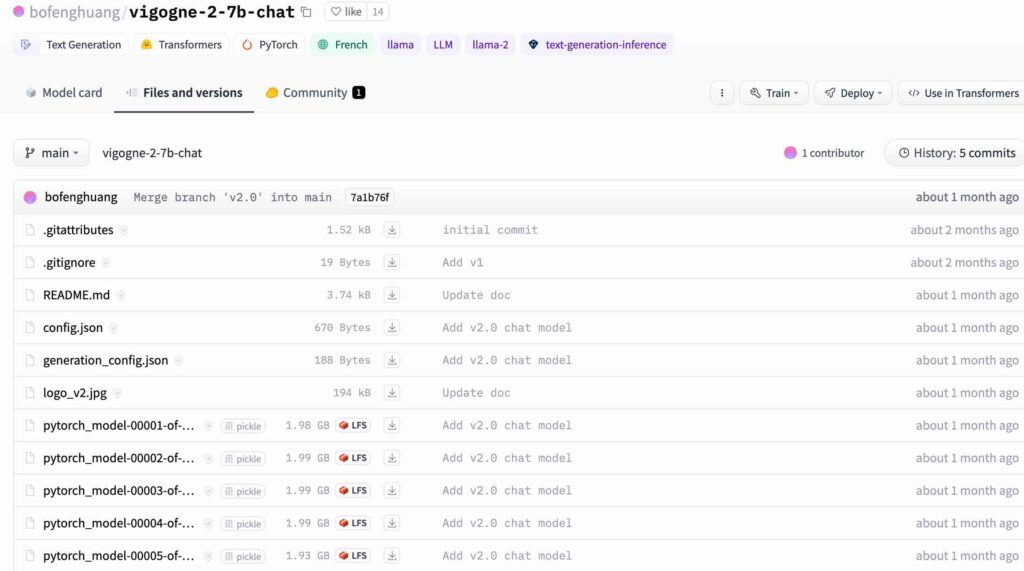
Pour cet article, j’ai donc jeté mon dévolu sur Vigogne 2 7B chat et comme vous pouvez le voir sur l’image juste au-dessus, les binaires découpés en parties qui font chacune quasiment 2 GB et la mention git LFS est bien indiquée dessus. Nous aurons l’occasion de reparler plus en détails de ce Vigogne V2 Chat dans un autre article, mais ici, on va se concentrer sur la récupération et la conversion de ce modèle en particulier en tapant la commande git suivante :
GIT_TRACE=1 git clone https://huggingface.co/bofenghuang/vigogne-2-7b-chatÉtant donné que je n’ai pas une connexion Internet très rapide où je me trouve actuellement, j’ai indiqué un paramètre en plus dans la commande pour voir ce qu’il se passait au fur et à mesure pour le rendre plus verbeux. Il s’agit du : GIT_TRACE=1 qui va me dire ce que git est en train de faire. Sinon, je me retrouvais à attendre sans savoir si cela avançait vraiment hormis regarder le trafic à partir de ma carte réseau. J’ai patienté un peu pour récupérer le dossier avec tous les binaires et les autres fichiers importants du dépôt de Vigogne AI qui sont hébergés sur Hugging Face.
Conversion du binaire vers le format GGUF
Normalement, vous devriez avoir Python qui est installé sur votre machine et si ce n’est pas le cas, je vous conseille vivement de l’installer pour passer à la suite. Sur Linux, c’est vraiment très simple et de toute façon ça, vous devrez vous resservir pour autre chose et c’est indispensable pour ce qui va suivre.
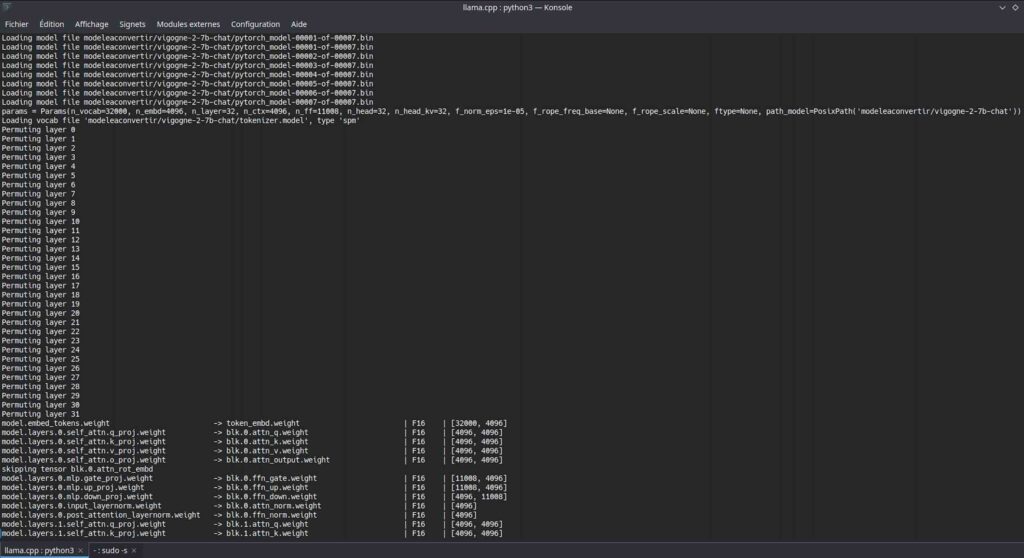
J’ai créé un dossier modeleaconvertir directement dans l’arborescence de mon précédent clone de Llama CPP, puis j’ai ajouté dedans le dossier entier de Vigogne 2. Il suffit alors de lancer la commande suivante pour lancer la conversion vers le format GGUF :
python3 convert.py ./modeleaconvertir/vigogne-2-7b-chatLa conversion se lance et il faudra patienter selon la puissance de votre ordinateur :
Une fois que le processus est terminé, il m’écrit un nouveau fichier gguf dans le dossier du modèle que l’on va donc pouvoir utiliser :
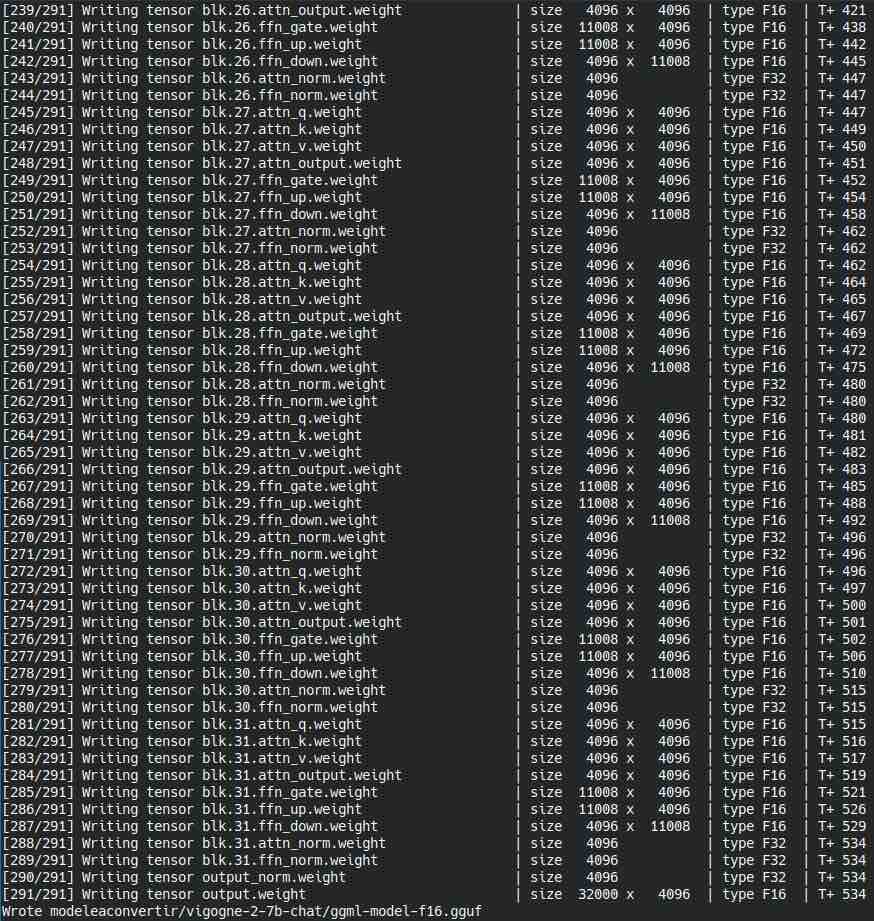
Comme vous le voyez, c’est très facile, mais j’ai décidé de faire ce tutoriel, car lorsque l’on débute, ce n’est pas forcément évident de retrouver les différentes informations utiles tellement le sujet de l’intelligence artificielle est vaste. Donc je me suis alors dit que ce serait intéressant de tout condenser dans un tutoriel. Attention, on reste simple et je ne cherche pas encore à faire de quantization, on garde les données intactes pour le moment, car on n’est pas encore dans l’optimisation.
D’ailleurs, si vous rencontrez l’erreur suivante :
File "/home/dev/Téléchargements/zonetuto/llama.cpp/convert.py", line 26, in <module>
from sentencepiece import SentencePieceProcessor # type: ignore
ModuleNotFoundError: No module named 'sentencepiece'Il suffit alors d’installer les librairies correspondantes pour résoudre le problème. Dans mon cas, un simple :
pip install sentencepieceSera largement suffisant pour poursuivre la conversion de mon modèle vers le format GGUF avec llama.cap. Sur une autre machine, je n’avais pas eu le souci, car j’avais déjà fait de l’intelligence artificielle avec Python3 dessus. Donc cela dépendra de votre contexte, mais je crois que sur une machine qui n’avait jamais vu de Python, c’est la seule chose que j’ai dû installer en plus. S’il vous manque d’autres choses suite à par exemple une mise à jour de Llama CPP , installez les de la même manière avec pip et tout devrait rouler. Quand ce sera fait et vous serez tranquille pour la suite de vos expériences avec l’intelligence artificielle si vous utilisez d’autres logiciels, car ils demandent globalement les mêmes dépendances Python.
Test de l’inférence de la conversion au format GGUF avec llama.cpp
Maintenant, pour terminer ce tutoriel avec llama.cpp et la conversion d’un modèle d’intelligence artificielle dans un autre format récupéré sur HuggingFace. Nous allons tout de même tester si l’inférence fonctionne. Ce serait dommage de faire tout ça si les choses ne fonctionnent pas sur votre distribution Linux adorée. À ce propos, n’oubliez pas que je vous avais présenté GPT4All dans cet article qui utilise d’ailleurs Llama CPP pour faire de l’inférence, mais cette fois avec une interface graphique qui ressemble fortement à ChatGPT.
Pour que les explications ne soient pas trop longues ici, on va le faire directement en dur avec LLama CPP et avec la simple commande suivante :
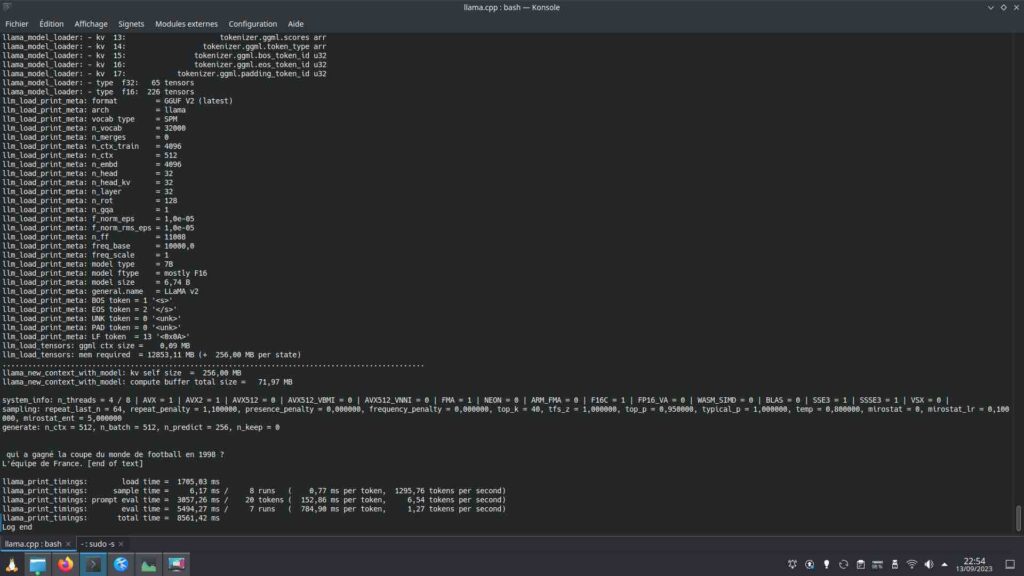
./main -m ./modeleaconvertir/vigogne-2-7b-chat/ggml-model-f16.gguf -n 128 -p "qui a gagné la coupe du monde de football en 1998 ?"Notre modèle d’IA se charge :
Très rapidement, sans aucune optimisation, j’ai la réponse à ma question en français :
Vous êtes maintenant capable de convertir des modèles d’intelligences artificielles récupérés sur HuggingFace pour les utiliser en local avec votre processeur via le logiciel open source llama.cpp. Il évolue d’ailleurs lui aussi très rapidement et je pense que je vais avoir prochainement l’occasion d’en reparler !
Bon sang, j’ai essayé de le compiler la semaine dernière et impossible et maintenant ça passe tout shuss.. Petite question, j’essaie de rajouter les format GUFF sous gtp4all mais ça ne semble pas prendre, pourtant sur leur site il annonce bien la prise en charge de ce format. J’ai pas tout comprendu m’sieur?