
Imaginez que vous êtes un analyste de données qui tente de recueillir des informations précieuses pour votre entreprise. Vous savez qu’une mine d’or d’informations se trouve sur un site Web particulier, mais il y a un obstacle majeur : le site est protégé par un WAF, ou un pare-feu d’application Web.
C’est un problème courant pour les spécialistes de la science des données et il peut sembler insurmontable. Mais ne vous inquiétez pas, nous avons une solution. Dans ce tutoriel, nous allons voir comment vous pouvez utiliser Python et Playwright pour extraire des données (scraping) d’un site Web protégé par WAF.
Avant de commencer, il est important de comprendre ce qu’est un WAF. La protection WAF (Web Application Firewall) est un mécanisme de sécurité qui protège les sites Web contre les attaques malveillantes en filtrant le trafic Web. Il analyse le trafic entrant et sortant du site Web pour détecter et bloquer les activités suspectes. Cela peut rendre l’extraction de données un défi, car le WAF peut interpréter ces activités comme une attaque sur le site.
Heureusement, Playwright, une bibliothèque d’automatisation des navigateurs Web, offre un moyen efficace d’extraire des données d’un site Web protégé par un WAF en utilisant Python.
Dans cet article, nous allons voir comment extraire des données (scraping) d’un site Web protégé par une authentification WAF à l’aide de Python et de Microsoft Playwright.
Qu’est-ce que Playwright ?
Playwright est une bibliothèque open-source développée par Microsoft qui permet d’automatiser les navigateurs Web, y compris Chrome, Firefox et WebKit. Elle offre une solution puissante pour interagir avec des pages Web, remplir des formulaires, cliquer sur des éléments et extraire des données, le tout en utilisant le langage de programmation Python.
Script d’extraction de données avec Playwright
1. Installation de Playwright
Pour commencer, vous devez installer Playwright. Utilisez pip pour installer la bibliothèque Playwright-Python en exécutant la commande suivante :
pip install playwrightAprès avoir installé Playwright, vous devez exécuter la commande playwright install. Cela permet de télécharger les binaires de navigateur dont Playwright a besoin pour automatiser les navigateurs.
playwright install2. Initialisation de Playwright
Importez Playwright et initialisez-le dans votre script Python. Vous devrez spécifier le navigateur que vous souhaitez utiliser, par exemple, Chrome, Firefox ou WebKit.
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch() page = browser.new_page()
3. Accéder au site Web
Utilisez la méthode goto pour accéder au site Web que vous souhaitez extraire.
page.goto("https://example.com")
4. Interaction avec la page Web
Si la page nécessite des interactions (par exemple, remplir un formulaire), vous pouvez utiliser les méthodes de Playwright pour effectuer ces actions. Par exemple, pour remplir un formulaire, utilisez fill :
page.fill("#username", "votre_nom_utilisateur") page.fill("#password", "votre_mot_de_passe")
5. Extraire les données
Maintenant, vous pouvez extraire les données de la page en utilisant des sélecteurs CSS, XPath ou d’autres méthodes de localisation d’éléments.
# Exemple d'extraction de texte title = page.inner_text("h1") print("Titre de la page :", title)
6. Fermer le Navigateur
N’oubliez pas de fermer le navigateur une fois que vous avez terminé.
browser.close()
Exemple
Pour ce tutoriel, nous allons simuler une connexion au site Ubersuggest. Pour ce faire, vous devez auparavant avoir créé un compte sur ce site.
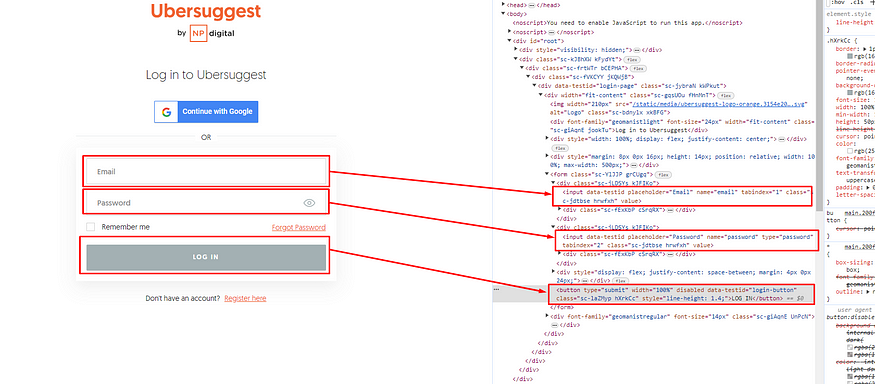
import logging # https://playwright.dev/python/docs/api/class-playwright from playwright.sync_api import sync_playwright if __name__ == "__main__": logging.basicConfig( format='%(asctime)s - %(levelname)s - %(message)s', datefmt='%Y/%m/%d %H:%M:%S', level=logging.INFO ) logging.info('Scraping website with WAF protection') with sync_playwright() as playwright: chromium = playwright.chromium browser = chromium.launch(headless = False) page = browser.new_page() # Log In page.goto("https://app.neilpatel.com/en/login") page.fill('[name=email]', 'your-email-here') page.fill('[name=password]', 'your-password-here') page.locator('css=button[data-testid="login-button"]').click() page.wait_for_timeout(3000) page.goto("https://app.neilpatel.com/fr/seo_opportunities") page.wait_for_timeout(7000) if "https://app.neilpatel.com/fr/seo_opportunities" in page.url: logging.info("Login successful") # Log Out # Click on hidden element page.locator('css=div[data-testid="sing-out"]').evaluate("node => node.click();") page.wait_for_timeout(3000) else: logging.error("Login failed") browser.close()
Ainsi, à travers cet exemple, nous avons pu nous connecter sur un site Web protégé par WAF.
Conclusion
En suivant les conseils de cet article, vous devriez être en mesure d’extraire des données d’un site Web avec protection WAF à l’aide de Python et Playwright. Cependant, il est important de noter que le web scraping peut être illégal dans certains cas. Il est donc important de vous assurer que vous avez le droit d’extraire les données que vous souhaitez.
N’oubliez pas que chaque site Web est différent, et ce qui fonctionne pour un site peut ne pas fonctionner pour un autre. Il faudra peut-être un peu d’expérimentation pour trouver la meilleure approche pour extraire des données d’un site Web spécifique. Mais avec de la patience et de la persévérance, vous pouvez surmonter les obstacles et obtenir les informations précieuses dont vous avez besoin
Alors, qu’attendez-vous ? Commencez à installer Python et Playwright et plongez dans le monde passionnant de l’extraction de données. Bonne programmation !